Wiki-память: персональная база знаний с AI
Wiki-память: персональная база знаний с AI-ассистентом
Как построить систему памяти для AI-ассистента, которая переживает сессии, накапливает знания и помогает принимать решения. Основано на идеях Андрея Карпати (LLM Wiki) и Дуга Энгельбарта (OHS Framework).
Это статья для тебя, если ты устал каждый раз объяснять Claude, кто ты, над чем работаешь и какие правила у вас уже договорены. Ты соберёшь wiki-память для AI, которая переживает сессии и накапливает знания, а не пересобирается с нуля. За 30 минут прочтения ты поймёшь архитектуру и увидишь как повторить её у себя.
Зачем тебе это знать
AI помнит тебя между сессиями. Ты один раз рассказал о проекте — завтра Claude уже в контексте. Не нужно повторять одно и то же в каждом новом чате.
Знания накапливаются, а не пересобираются. В отличие от RAG, wiki-память компилирует информацию один раз и обновляет её, а не роют каждый запрос заново.
Решения остаются найденными. Ты выбрал стек, понял почему так, потом столкнулся с неочевидными последствиями — wiki запомнит и контекст, и причину. Через полгода не нужно вспоминать «а почему ты так решил».
Проблема
AI-ассистент (Claude, GPT, Gemini) не помнит ничего между сессиями. Каждый разговор начинается с нуля. Ты объясняешь одно и то же снова и снова: кто ты, над чем работаешь, какие решения принимал, какие правила действуют.
RAG (загрузка документов) частично решает это, но LLM каждый раз заново ищет и собирает ответ из фрагментов. Ничего не накапливается.
Решение: LLM Wiki
Идея Андрея Карпати: вместо RAG, LLM постепенно строит и поддерживает wiki — структурированную коллекцию markdown-файлов с перекрёстными ссылками. Знания компилируются один раз и обновляются, а не пересобираются заново на каждый запрос.
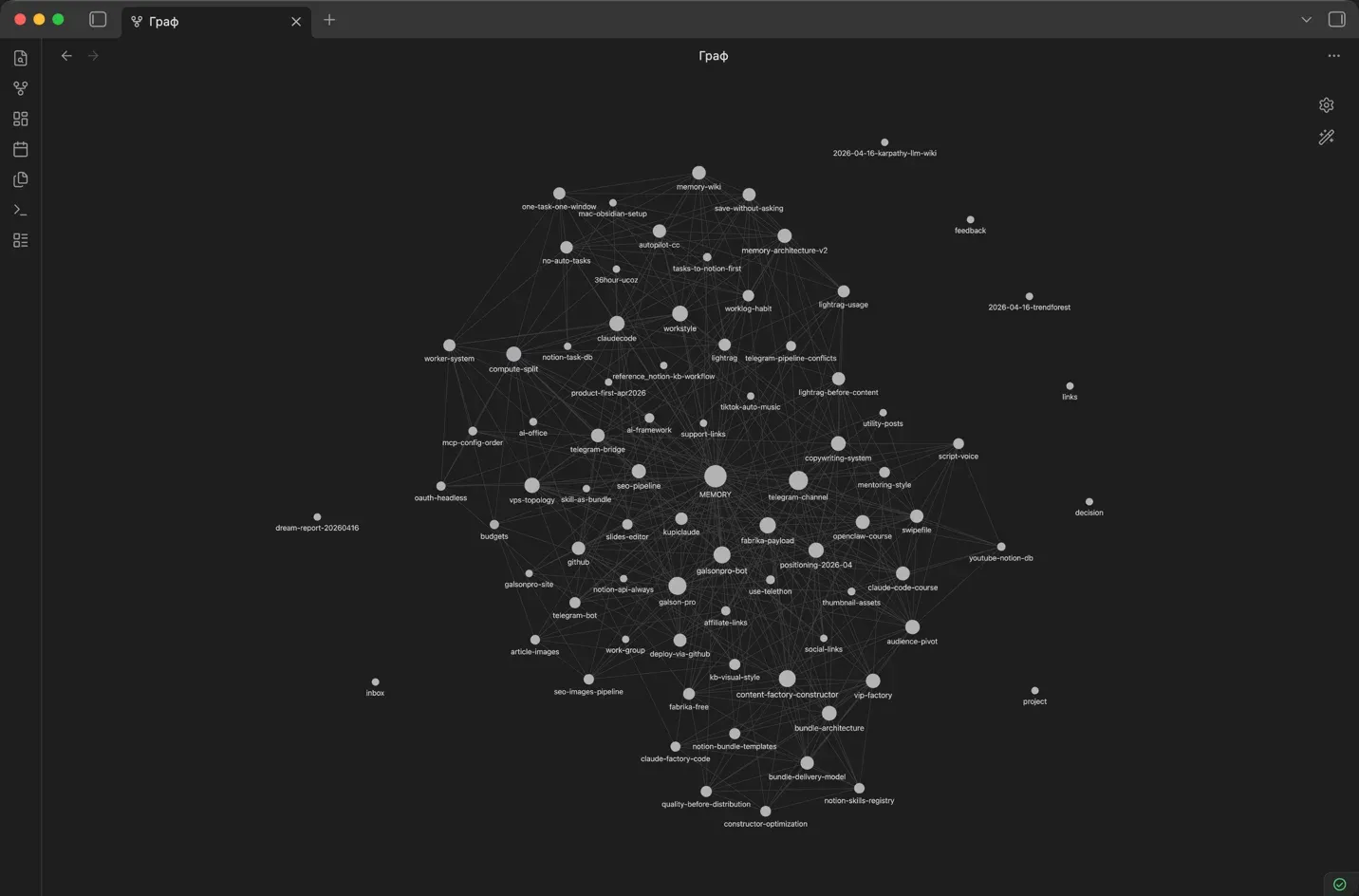
Три слоя архитектуры
1. Raw sources (неизменяемые) — ваши документы, статьи, скриншоты. LLM читает, но не трогает.
2. Wiki (LLM-генерируемая) — страницы с саммари, сущностями, решениями, перекрёстными ссылками. LLM пишет и обновляет всё.
3. Schema (CLAUDE.md) — конфигурация, которая объясняет LLM как устроена wiki, какие правила оформления, какие рабочие процессы.
Три операции
— Ingest — добавить новый источник. LLM читает, извлекает ключевое, обновляет wiki-страницы, добавляет в индекс.
— Query — задать вопрос wiki. LLM ищет релевантные страницы, синтезирует ответ. Хорошие ответы сохраняются обратно в wiki.
— Lint (Dream) — здоровье wiki. Найти противоречия, orphan-страницы (страницы, на которые никто не ссылается — они теряются в базе), сломанные ссылки, устаревшие данные.
Попробуй сам. Спроси Claude «что ты знаешь обо мне и моих проектах?» и посмотри, на какие страницы он сошлётся. Если ответ размытый — значит, MEMORY.md не структурирован или страницы остались orphan.
Dream Script — ночная консолидация
По аналогии с Anthropic Memory (dreaming) — AI-ассистент периодически "спит" и наводит порядок в базе знаний:
— Inbox cleanup — обработать новые заметки, раскидать по категориям, удалить старые
— Broken links — найти и починить [[ссылки]] в никуда
— Orphan pages — найти страницы без входящих ссылок, привязать к хабам
— Stale pages — пометить устаревшие страницы (>60 дней без обновления)
— Frontmatter audit — проверить что все метаданные на месте (тип, теги, источник)
Запускается как cron-скрипт через Claude Code в headless-режиме. Claude Sonnet обходит все файлы, находит проблемы, исправляет, пишет отчёт.
Попробуй сам. Запусти lint вручную: claude -p "пройдись по wiki/, найди broken links и страницы без входящих ссылок". Получишь отчёт за пару минут — поймёшь, где база знаний дрейфует от реальности.
Структура wiki
wiki/
MEMORY.md # индекс — загружается каждую сессию
_templates/ # шаблоны страниц
inbox/ # входящие заметки (Telegram, голос, фото)
projects/ # страницы проектов
decisions/ # принятые решения (почему X, а не Y)
feedback/ # правила работы (делай так, не делай так)
references/ # внешние ресурсы, креды, пайплайны
user/ # профиль пользователя, стиль работыИнструменты
— Obsidian — IDE для wiki. Визуализация графа связей, навигация по [[ссылкам]], плагины Dataview и Web Clipper.
— qmd — локальный поиск по markdown — локальный поиск по markdown (BM25 + vector). On-device, без API. MCP-сервер для Claude. Подробнее — на отдельной странице.
— Syncthing — синхронизация wiki между устройствами (VPS ↔ Mac ↔ ноутбук).
— Telegram Bot — мобильный ввод. Текст, голос, фото → inbox. Gemini Vision для распознавания скриншотов.
Мобильный ввод через Telegram
Telegram-бот в форум-группе с топиком Notes. Всё что туда падает → сохраняется в wiki/inbox/ как markdown файл:
— Текст → сохраняется как есть с тегами
— Голосовое → транскрибируется (Whisper) → сохраняется
— Фото/скриншот → описывается (Gemini Vision) → сохраняется с тегом "скриншот"
Типичные страхи и ошибки
Ошибка: копить inbox без разбора. Решение — Dream-скрипт по ночам: чистит inbox, находит страницы без входящих ссылок, помечает устаревшее. Плюс compaction: append-only inbox раз в неделю разгребается вручную (или LLM-скриптом) в тематические страницы.
Ошибка: доверять LLM на 100% и не проверять страницы. Поэтому в каждой странице указывай источник: source: human или source: llm. LLM-страницы периодически вычитывай сам. Когда файлов станет 300+ — подключай поиск qmd, при 1000+ — возможно нужна настоящая база данных (PostgreSQL, SQLite).
Ошибка: держать wiki на одной машине без синхрона. Syncthing синхронизирует wiki по всем машинам без облака, а git делает версионность и rollback, если что-то сломалось. VPS, Mac и ноутбук видят одни и те же markdown-файлы.
Проверь себя
1Чем LLM Wiki принципиально отличается от RAG?
2Какие три операции у wiki?
3Что такое orphan-страница?
4Зачем нужен Dream Script?
5Где хранится [MEMORY.md](http://memory.md/) и зачем?
6Почему qmd работает на устройстве, а не в облаке?
Источники
— Andrej Karpathy — LLM Wiki (GitHub Gist, April 2026)
— Doug Engelbart — Open Hyperdocument System (OHS) Framework
— Anthropic — Memory & Dreaming (Claude 4.5, 2026)
— Niklas Luhmann — Zettelkasten method (90,000 карточек)
— Tobi Lutke (Shopify) — qmd: local markdown search engine