Архитектура памяти Claude Code — 3 слоя, чтобы AI не забывал
Как сделать чтобы Claude Code помнил тебя, твой проект и прошлые решения без ручного ведения файлов. Разбираем три слоя памяти: короткую (Wiki), длинную с умным поиском (LightRAG) и журнал активности (session logs).
Зачем тебе это знать
Claude не забывает контекст проекта. Каждая новая сессия начинается с того места, где ты закончил. Без «напомни мне что мы вчера делали».
Один раз записал в память — больше не повторяешь. Сказал «не деплой без бэкапа» — Claude сам подтянет это напоминание в следующих сессиях.
Собирается живая база знаний проекта. Через месяц у тебя актив со всеми решениями и правилами, который работает даже без тебя: в новой сессии или у коллеги.
Проблема
Claude Code не помнит ничего между сессиями. Каждый новый разговор — чистый лист. Есть файлы CLAUDE.md и auto-memory (Markdown-файлы памяти), но ты обновляешь их вручную и они быстро устаревают.
Я настроил LightRAG (база знаний с умным поиском по смыслу), но забыл подключить её к рабочему потоку. Результат: неделя настройки, а база пустая. Мёртвый архив.
Главный урок
Никогда не ставь инфраструктуру без feedback loop. Если поднял базу данных, но не подключил к ней ЗАПИСЬ и ЧТЕНИЕ в рабочем потоке — это мёртвый архив. Подход «поставлю сейчас, подключу потом» = «не подключу никогда».
Feedback loop — это замкнутый круг: ты работаешь → данные автоматически уходят в память → при следующей сессии Claude автоматически достаёт их обратно. Без двух этих стрелок память не живёт.
Три слоя памяти
Каждый слой решает свою задачу. Вместе они дают ощущение что Claude «помнит».
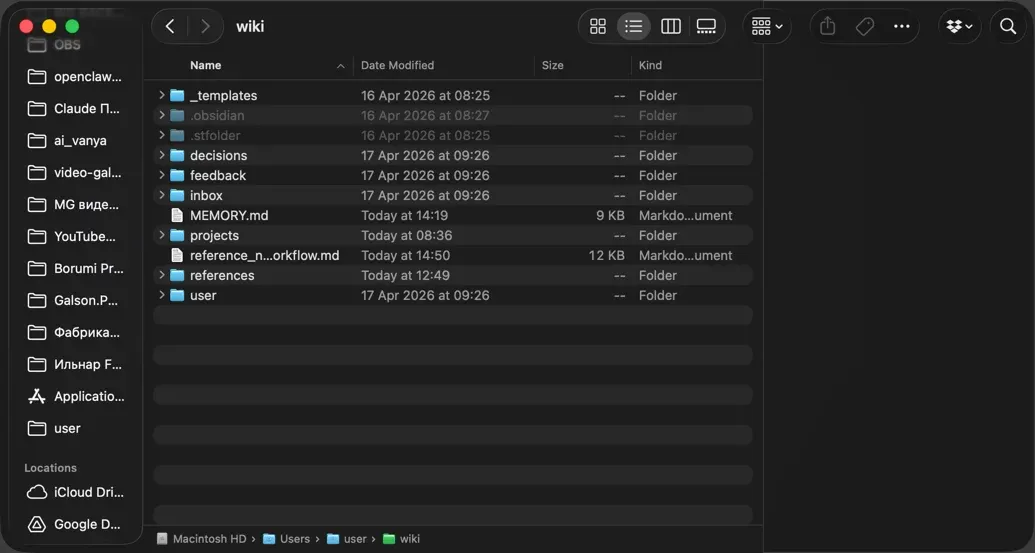
Слой 1: Wiki — короткая память
Это Markdown-файлы в папках user/, projects/, decisions/, feedback/, references/. Индекс MEMORY.md загружается автоматически в каждую сессию. Синхронизируется между устройствами через Syncthing (программа которая копирует папки между Mac и сервером).
В Wiki хранится короткое и сформулированное:
— что решили («деплой только через GitHub»)
— что не делать («никогда не коммить node_modules»)
— факты о проекте (путь к конфигу, название базы)
Слой 2: LightRAG — длинная память с умным поиском
Это база на сервере которая умеет отвечать по смыслу, а не по имени файла. Работает так:
1. Текст разбирается на «сущности» (проект, команда, решение) — строится граф связей
2. Параллельно каждый кусок текста превращается в вектор — набор из 768 чисел. Похожие по смыслу куски оказываются рядом в математическом пространстве.
Ты спрашиваешь «как мы деплоим?» — система ищет по всей базе по смыслу. Находит ответ даже если в самом тексте слова «деплой» не было, а было «публикую сайт».
Аналог — Pinecone (нейронная память в n8n), но self-hosted (работает на твоём сервере) и бесплатный. Плюс граф связей.
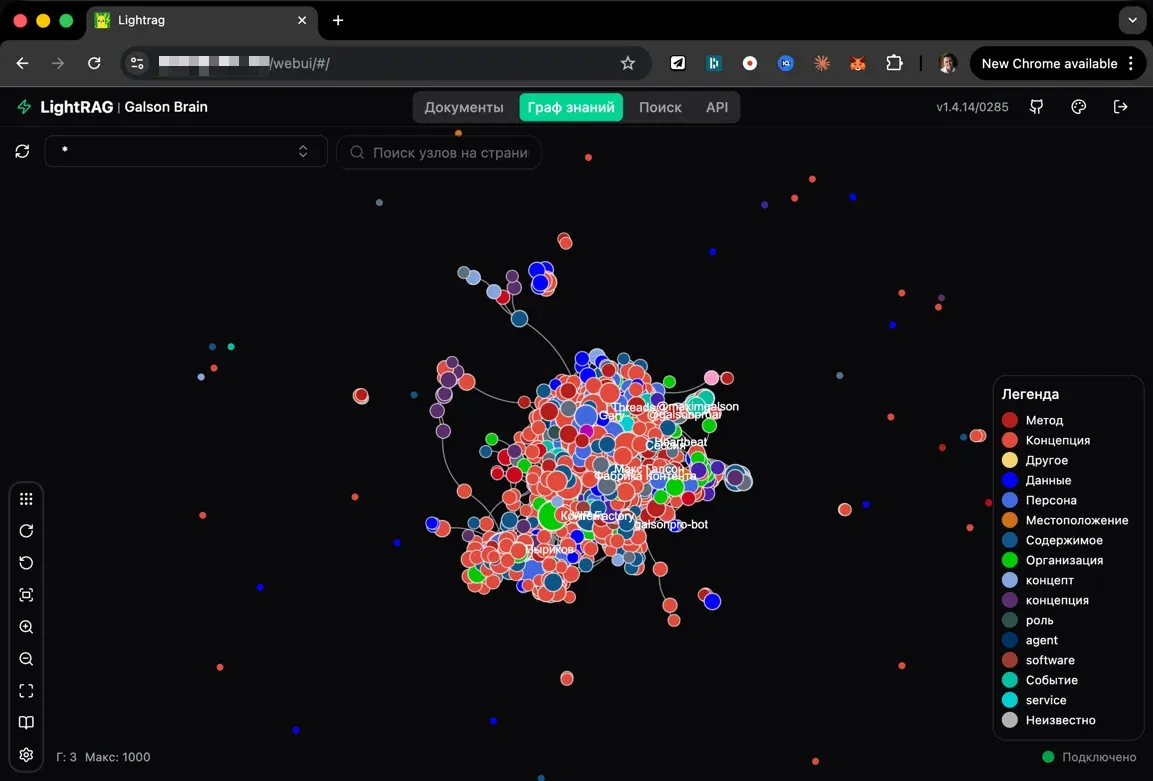
Слой 3: Session logs — журнал активности
JSON-файлы которые пишутся после каждой сессии: какие файлы менялись, какие команды запускались, git diff (разница между версиями файлов), краткая сводка. Это не «что решили», а «что я делал».
Как это работает
Запись — автоматически при завершении сессии
Каждый раз когда сессия заканчивается, срабатывают хуки Claude Code (хук — это скрипт который автоматически запускается на определённое событие):
— PostToolUse хук накапливает контекст прямо во время работы: файлы, команды, счётчик tool-вызовов
— Stop хук (autosave v5.3) одновременно отправляет данные в три места: session log, Wiki, LightRAG
— Воскресный крон пересобирает все Wiki-файлы в LightRAG заново — чтобы ручные правки тоже попали в граф
Чтение — автоматически при старте сессии
Когда ты начинаешь новый разговор с Claude:
— CLAUDE.md и MEMORY.md загружаются в контекст ВСЕГДА — это «короткая память»
— SessionStart хук идёт в LightRAG и спрашивает: «дай топ-5 релевантных фактов по текущему проекту»
— Результат прилетает в системный промпт — Claude видит это как обычный контекст и учитывает в ответах
Попробуй сам. Создай свою Wiki с одной записью.
В следующей сессии Claude увидит этот индекс и будет знать о проекте alpha. Дальше можно подключить LightRAG — с уже работающей памятью.
Типичные страхи и ошибки
«Настроил LightRAG и забыл использовать»
Самая частая ошибка. Поставил Docker, настроил embedding-модель (алгоритм превращения текста в числа), порадовался, а база стоит пустая. Решение: прописывай хуки ВНАЧАЛЕ. Сначала отвечаешь на вопросы «как попадёт туда запись?» и «как оттуда пойдёт чтение?» — только потом ставишь инфраструктуру.
«Wiki устарела за 3 дня»
Если обновляешь вручную — не успеешь. Нужна автозапись. Stop хук в autosave.js — единая точка входа для всех записей. Руками трогаешь только в редких случаях.
«Все файлы свалены в одну кучу»
Без структуры Wiki превращается в свалку. Папки обязательны:
`user/` — Про тебя: стиль работы, предпочтения, роль в проекте
`projects/` — Про проекты: что делает, где лежит, кто владеет
`decisions/` — Что решили: архитектурные выборы, процессы команды
`feedback/` — Что не делать: прошлые ошибки, корректировки курса
`references/` — Полезные ссылки: API (интерфейсы сервисов), документация, ключи доступа
«Память растёт бесконтрольно»
Со временем LightRAG забивается дубликатами и устаревшими записями. Воскресный крон lightrag-hygiene.sh чистит старьё и перестраивает граф заново.
Технический стек для справки
**Wiki-память** — Markdown-файлы в ~/claudecode/wiki/. Синхронизация между Mac и сервером (VPS — виртуальный сервер в облаке) через Syncthing (syncthing.net) — бесплатная программа которая держит папки одинаковыми на всех устройствах
**LightRAG v1.4.13 (github.com/HKUDS/LightRAG)** — База знаний с умным поиском. Запускается в Docker (контейнер с программой — работает одинаково на любом компьютере) на сервере. Использует нейросеть Gemini 2.5 Flash через OpenRouter (openrouter.ai) — единый доступ к десяткам LLM по одному API. Embedding-модель ollama/nomic-embed-text превращает текст в векторы чисел. Веб-интерфейс на своём домене или localhost (твой компьютер)
Хуки Claude Code — Скрипты на Node.js которые срабатывают автоматически: ap-autosave.js — при завершении сессии (Stop), ap-dashboard.js — при старте сессии (SessionStart), ap-context-monitor.js — после каждого вызова инструмента (PostToolUse)
Вспомогательные библиотеки — lib/lightrag.js, lib/wiki.js, lib/memory.js — общий код для работы с базой и Wiki
Крон (задание по расписанию) — lightrag-hygiene.sh запускается воскресеньем в 3:00 ночи: чистит дубликаты и пересобирает граф
Пример из моей настройки. Когда я правильно подключил хуки, база наполнилась почти в 4 раза (114 документов → 430+). Стало ясно что раньше я просто не писал в память регулярно. Сейчас каждая сессия сама пишет в Wiki и LightRAG, сама читает на старте. Граф сущностей видно на graph.galson.pro. Память растёт без моего участия — это и есть рабочий feedback loop.
Проверь себя
1Почему LightRAG называют «векторной памятью»?
2Что обязательно сделать одновременно с установкой новой базы данных для памяти Claude?
3Зачем нужен Stop хук в Claude Code?
4В чём разница между Wiki и LightRAG в этой системе памяти?
5Почему нельзя обновлять Wiki только вручную?
6Что происходит в SessionStart хуке?